INTRO
Scopri come pulire ed unire più fogli Excel con strutture variabili in un’unica tabella, automatizzandone il processo e senza ricorrere a soluzioni hard-coded.
Contesto
Nelle realtà aziendali odierne capita sempre più di frequente di lavorare con fogli Excel provenienti da reparti differenti, ognuno caratterizzato da piccole discrepanze nella struttura—intestazioni non uniformi, colonne aggiuntive o mancanti, ordini variabili. Il risultato è un’attività manuale di pulizia e consolidamento che diventa rapidamente ripetitiva, incline a errori e difficile da mantenere nel tempo. In questo articolo esploreremo come, applicando best practice consolidate con Power Query, sia possibile automatizzare completamente il processo di preparazione dei dati, garantendo al contempo flessibilità e semplicità di manutenzione.
Scenario
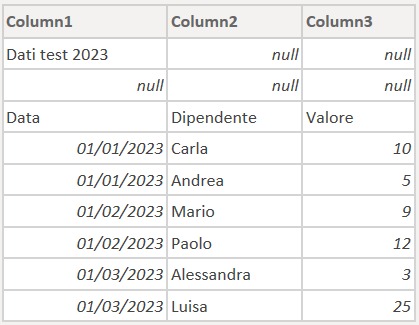
Nel file Excel fornito dalla Responsabile HR, troviamo diversi fogli di lavoro: tre contengono i punteggi dei dipendenti sui test svolti negli anni 2023, 2024 e 2025, mentre gli altri sono riferiti a bozze o dati di supporto non rilevanti per l’analisi richiesta. L’obiettivo è estrarre automaticamente solo quei tre fogli contenenti i voti conseguiti, uniformarne le intestazioni e il layout, e combinarli in un’unica tabella centrale pronta per essere caricata su Power BI o Excel, eliminando manualità e minimizzando il rischio di errori.
Inoltre, il flusso automatizzato dovrà essere progettato in modo che, qualora vengano aggiunti in futuro nuovi fogli con i risultati di anni successivi, Power Query sia in grado di riconoscerli, importarli e formattarli senza alcuna modifica manuale.
Scomposizione funzionale
Per costruire un’automazione solida, il primo passo è scomporre l’intero processo in micro-task distinti e ben definiti. Questo approccio permette di:
- Identificare chiaramente le responsabilità di ogni fase (connessione alla sorgente, filtro dei fogli, promozione intestazioni, unione dei dati, ecc.).
- Facilitare il testing e il debug, isolando eventuali errori in uno specifico sotto-flusso senza impattare l’intero processo.
- Garantire riusabilità e manutenibilità, perché ogni micro-task può essere modificato o sostituito senza dover riscrivere tutto lo script.
- Semplificare l’adeguamento a cambiamenti futuri, aggiungendo o rimappando singoli task anziché rifattorizzare interi blocchi di codice.
In questo modo, anche quando cambieranno i formati dei nuovi file Excel o si dovranno inserire ulteriori controlli di qualità, basterà intervenire sul micro-task corrispondente, mantenendo il flusso generale stabile e scalabile.
1DEFINE2 MEASURE Sales[Test] =3 CALCULATE ( 4 SUM ( Sales[Quantity] ),5 ALL ( 'Product'[ProductKey] )6 )7EVALUATE8ADDCOLUMNS (9 VALUES ( 'Product'[Color] ),10 "Test", [Test]11)Eseguendo il run ottieni questi risultati
| Color | Test |
|---|---|
| Silver | 27.551 |
| Blue | 8.859 |
| White | 30.543 |
| Red | 8.079 |
| Black | 33.618 |
| Green | 3.020 |
| Orange | 2.203 |
| Pink | 4.921 |
| Yellow | 2.665 |
| Purple | 102 |
| Brown | 2.570 |
| Grey | 11.900 |
| Gold | 1.393 |
| Azure | 546 |
| Silver Grey | 959 |
| Transparent | 1.251 |
Struttura Operativa del Flusso:
In questa sezione descriviamo sinteticamente i quattro passaggi chiave del processo ETL: dalla connessione e filtraggio iniziale dei fogli Excel, passando per la pulizia e l’espansione dei dati, fino alla formattazione finale. Ogni step è pensato per essere automatizzato e facilmente manutenibile, in modo da accogliere senza modifiche manuali l’arrivo di nuovi fogli annuali.
-
- Caricamento e filtraggio dei fogli
Connessione al file Excel e selezione automatica dei fogli il cui nome rappresenta un anno (solo numerici).- Approccio: definire un path applicativo per leggere il workbook e filtrare via M tutti i record in cui [Name] non è un numero.
- Funzioni: Excel.Workbook, File.Contents, Table.SelectRows
- Codice applicato: (snippet)
Excel.Workbook(File.Contest("C:\Users\matte\Desktop\Risultati Test.xlsx), null, true), Filtro_Valori_Numerici = Table.SelectRows(Origine, each not (try Number.FromText([Name]))[HasError]),
- Pulizia dei fogli (4 scenari)
Rimozione dinamica delle righe pre-header indipendentemente dalla loro posizione, usando quattro livelli di logica crescente.-
- Approccio: testare metodi differenti per individuare il primo record utile:
-
- salto fisso di X righe (snippet)
Rimozione_Prime_Righe_Hard_Coded = Table.Skip(Subset_Test,6) - salto fino al primo occorrere di “Data”
Rimozione_Prime_Righe_A_Schema_Fisso = Table.Skip(Subset_Test, each [Column1] <> "Data") - salto fino a righe contenenti null
- salto basato su riconoscimento libero del campo “Data”
- salto fisso di X righe (snippet)
- Funzioni: Table.Skip, List.Contains, Record.ToList, Table.PromoteHeaders
-
- Approccio: testare metodi differenti per individuare il primo record utile:
-
- Espansione e pulizia dei campi
Eliminazione dei metadati non necessari e srotolamento della colonna “Data” in campi distinti (Dipendente, Valore).-
-
- Approccio: rimuovere le colonne Item, Kind, Hidden e quindi espandere la tabella nidificata
- Funzioni: Table.RemoveColumns, Table.ExpandTableColumn
-
-
- Etichettatura e formattazione finale
Ridenominazione del campo Name in Anno per rendere esplicito l’anno di riferimento nel modello.-
- Approccio: applicare un semplice Rename per allineare le intestazioni al reporting
- Funzioni: Table.RenameColumns
-
- Caricamento e filtraggio dei fogli
Approcci di pre-header: analisi e rating
Prima di promuovere le intestazioni, è fondamentale eliminare le righe “pre-header” che precedono i veri nomi di colonna. In Power Query ciò si ottiene principalmente con la funzione Table.Skip, che scarta un numero di righe specificato o calcolato dinamicamente, restituendo la porzione di tabella utile per la promozione delle intestazioni. Di seguito quattro strategie, ordinate da quella più semplice e fragile a quella più flessibile e robusta:
-
- Skip fisso
Utilizza Table.Skip(table, N) per rimuovere sempre le prime N righe (p.es. 6).
Dettagli: rapidissimo da implementare via interfaccia (wizard) o M, ma si rompe al minimo spostamento: ogni nuova riga introdotta varia l’offset e richiede manutenzione manuale. - Skip a schema fisso
Scorre riga per riga finché non trova un valore noto in colonna (ad esempio “Data”) usando Table.Skip(table, each [Column1] <> “Data”).
Dettagli: più resiliente rispetto al skip fisso, perché si adatta a leggeri spostamenti verticali dell’intestazione, purché il valore di ricerca rimanga identico. - Skip a schema libero
Individua la riga header valutando il contenuto di ogni record:
- Skip fisso
m
CopiaModifica
Table.Skip(table, each not List.Contains(Record.ToList(_), “Data”))
Dettagli: funziona anche se l’intestazione contiene più colonne variabili, basta che una di esse includa la parola-chiave; richiede però un minimo di conoscenza M per comporre Record.ToList.
- Skip a schema dinamico
Elimina tutte le righe con celle vuote (null) fino alla prima riga completamente popolata:
m
CopiaModifica
Table.Skip(table, each List.Contains(Record.ToList(_), null))
Dettagli: massima flessibilità su layout eterogenei: non presuppone né nomi fissi né posizioni predefinite, ma richiede attenzione a file che possano avere righe ibride (alcune celle piene, altre vuote).
I frammenti completi di M-Code per ciascun approccio saranno mostrati in calce.
let
Origine = Excel.Workbook(File.Contents("C:\file.xlsx"), null, true)
in
Origine
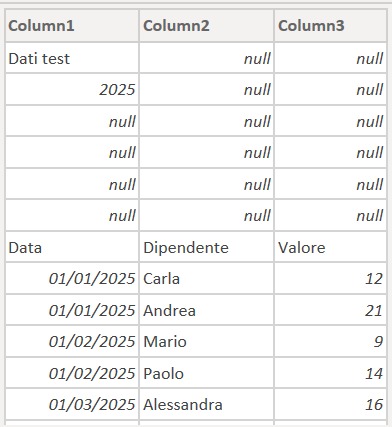
Tabella di rating
| Approccio | M-Code Skills | Uso Wizard/UI | Robustezza / Manutenibilità |
|---|---|---|---|
| 1. Skip fisso | ★☆☆☆☆ | ★★★☆☆ | ★☆☆☆☆ |
| 2. Skip a schema fisso | ★★☆☆☆ | ★★☆☆☆ | ★★☆☆☆ |
| 3. Skip a schema libero | ★★★☆☆ | ★☆☆☆☆ | ★★★☆☆ |
| 4. Skip a schema dinamico | ★★★★☆ | ★☆☆☆☆ | ★★★★★ |
Con questo confronto dettagliato potrai selezionare l’approccio più adatto al tuo scenario, bilanciando rapidità di sviluppo, livello di personalizzazione e capacità di evolvere senza interventi manuali
Gestione delle colonne: TransformColumns vs AddColumn
Nel flusso descritto finora abbiamo usato Table.TransformColumns per sovrascrivere la colonna Data esistente con la versione “pulita” (header promossi e pre-header rimossi). In alternativa è possibile utilizzare Table.AddColumn per creare una nuova colonna — ad esempio Nuova Colonna Data — lasciando intatta la colonna originale e proseguendo l’elaborazione sulla copia:
m
CopiaModifica
// Trasformazione in-place (sovrascrive [Data])
Modifica_Colonna_Esistente =
Table.TransformColumns(
Filtro_Valori_Numerici,
{ “Data”, each Table.PromoteHeaders(Table.Skip(_, each List.Contains(Record.ToList(_), null))) }
)
// Aggiunta di una nuova colonna (mantiene [Data] e crea [Nuova Colonna Data])
Aggiungi_Colonna_Con_Modifiche =
Table.AddColumn(
Filtro_Valori_Numerici,
“Nuova Colonna Data”,
each Table.PromoteHeaders(Table.Skip([Data], each List.Contains(Record.ToList(_), null)))
)
- Impatto su memoria e performance
-
- TransformColumns opera in-place: non duplica la tabella, quindi richiede meno memoria e tende ad essere più rapido.
- AddColumn genera una struttura dati più pesante, poiché mantiene entrambe le colonne (originale e nuova) fino alla successiva rimozione di quella obsoleta.
- Chiarezza del modello
- Con AddColumn è più semplice confrontare — in fase di debug o sviluppo — i dati “prima” e “dopo” la pulizia, conservando la colonna originale fino a rimuoverla espressamente.
- TransformColumns nasconde il passaggio intermedio, rendendo lo script più lineare ma meno “verboso” nella storia delle trasformazioni.
- Manutenibilità
- Se prevedi di fare ulteriori controlli di qualità (es. validazione del risultato di PromoteHeaders), l’approccio con AddColumn consente di ispezionare il contenuto netto senza sovrascrivere immediatamente l’originale.
- Se invece il requisito è semplicemente pulire e passare oltre, TransformColumns è più elegante e performante.
Quando scegliere cosa?
- Produttivo e performante: preferisci Table.TransformColumns se il flusso è maturo e non richiede debug delle versioni intermedie.
- Sviluppo e debug: usa Table.AddColumn nelle fasi iniziali per poter ispezionare agevolmente i risultati intermedi; in seguito potrai sostituirlo con TransformColumns per ottimizzare il codice finale.
Conclusioni
In questo articolo abbiamo esplorato come trasformare un’operazione ripetitiva e soggetta a errori—la pulizia e l’unione di fogli Excel eterogenei—in un flusso completamente automatizzato con Power Query. Abbiamo visto:
- Come connettersi dinamicamente a un workbook e filtrare soltanto i fogli di interesse (anni numerici).
- Quattro strategie per individuare e rimuovere le righe di pre-header, valutate con uno scoring su competenze M, uso dell’interfaccia e manutenibilità.
- I passaggi di espansione, promozione intestazioni e rinomina colonne per ottenere una tabella uniforme, pronta per il modello Power BI o per Excel.
Spunti Futuri
- Estendere il pattern ai nuovi formati di file (CSV, JSON, cartelle SharePoint) utilizzando funzioni analoghe di Power Query.
- Introdurre controlli di qualità dati (es. validazione valori, gestione anomalie) in ulteriore micro-task.
- Sperimentare con Power Automate o Azure Data Factory per schedulare l’esecuzione del flusso in cloud.
Prova subito il file di esempio e il template M-Code allegati per replicare questo flusso nel tuo progetto: ti basterà modificare il percorso del file per metterlo subito in produzione. Se ti è stato utile, condividi questo articolo e iscriviti alla newsletter per ricevere altri tutorial avanzati su Power Query e Power BI